On the 20th of January 2025 (a market holiday in the U.S.), China’s Hangzhou DeepSeek Artificial Intelligence Basic Technology Research Co., Ltd – now better known as simply “DeepSeek” – announced that it is allowing public access to its large language model (LLM) named “DeepSeek-R1“. Initial tests1 of R1 showed that its performance on certain tasks in chemistry, mathematics and coding was on par with that of Microsoft partner OpenAI’s model o1 – which was quite vaunted2 in these areas.
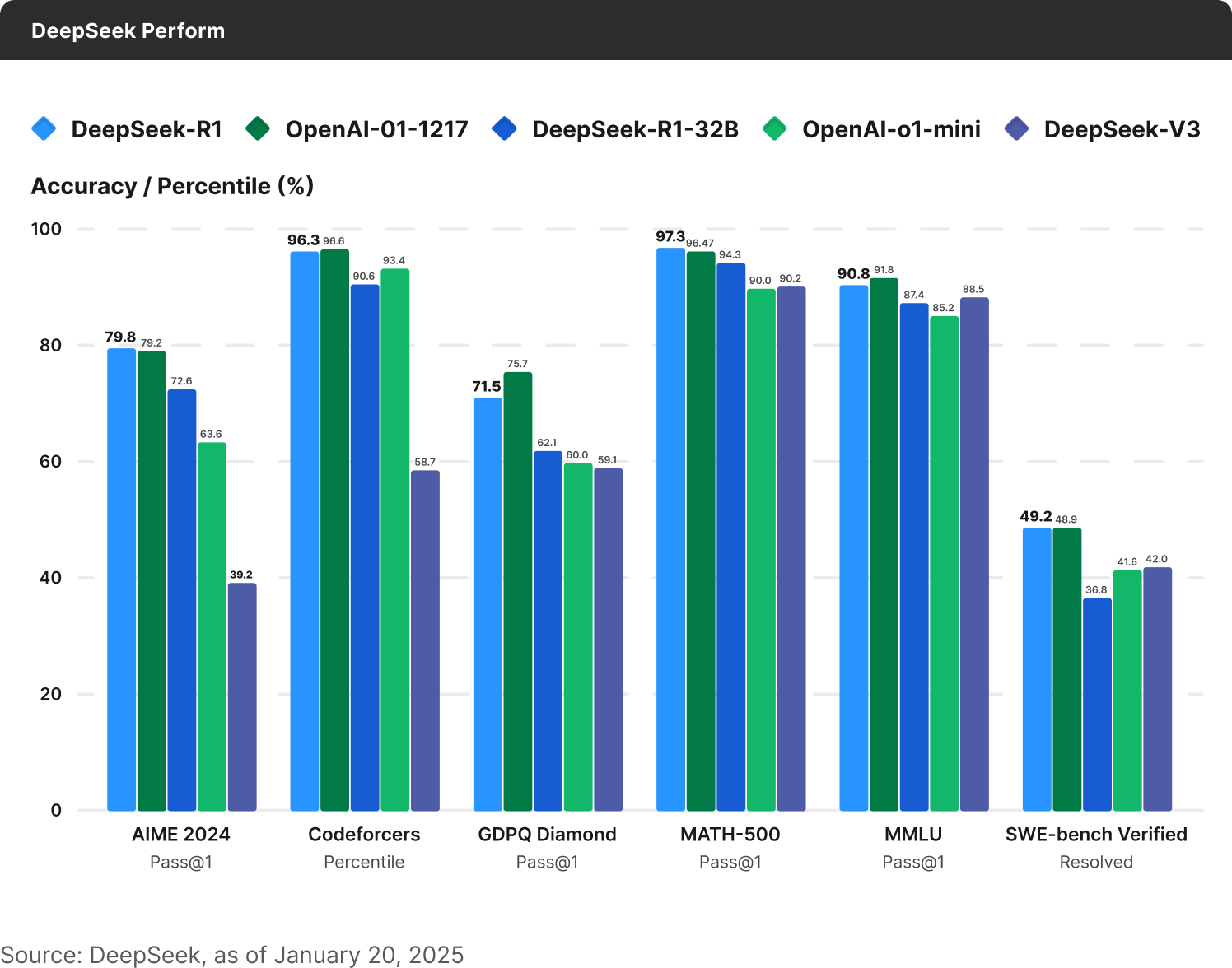
DeepSeek reported that it attained massive improvements over previous accuracy estimates by “distilling” from other open-source models frameworks, notably Alibaba’s Qwen and Meta Platforms’ Llama models. The process of “distillation” can roughly be explained thus3: the larger model (like, say, the “base” DeepSeek-R1 model) is less efficient since it processes along more parameters. Generally speaking, the larger the number of parameters, the harder it is to be sustainably accurate unless a lot of computation power is deployed to crunch large volumes of data. So, to improve this, smaller models working with fewer parameters use the computation results of the larger model as a “teacher” or a baseline reference to be more efficient in arriving at a more accurate conclusion. Theoretically, this could become a two-way street between “teacher” and “student”: the smaller model’s efficiency could possibly be replicated into the next iteration in the larger one, making the next generation of “students” possibly even smaller or more accurate.
In DeepSeek’s case, it referenced the open-source work of China-based Alibaba and U.S.-based Meta. In turn, Alibaba’s Qwen model itself was a “teacher” to Stanford University’s S1 model that also distilled from Google’s Gemini Thinking Experimental model4 to outperform OpenAI’s model on a set of curated questions.
Thus, while media agencies might be construed as hyping the growing capabilities of Chinese AI companies, the fact is that this is less a notch for any single organization of a specific national provenance. Instead, it’s mostly an achievement of the open-source developers’ community flourishing all over the world, including in Silicon Valley, Wall Street (to an extent), leading universities and more.
“Open-Source” and Copyright Laws
DeepSeek itself, however, isn’t open-source in the strictest sense. Instead, they have been mostly “open-weight”, i.e. while the algorithm’s results can be studied and the algorithm can be used as a base to build on, the training data and code itself are not made available to the public. This in itself, however, was an improvement over other more popular LLM providers. For instance, Sam Altman-led OpenAI — which originally started under the aegis of being a “non-profit” seeking funding for research that would be made available to the world — closed off the public’s access to their code’s inner workings after the launch of GPT-45.
One month after it published results comparing its latest accuracy results versus OpenAI, DeepSeek announced plans6 to share the code repository of five of its “online services”, i.e. the likes of chatbots, search aggregators, etc., with the public. Sam Altman went on to say that OpenAI might be on “the wrong side of history”7 regarding the open-sourcing of its technologies and admitted that it’s likely that the company will progressively maintain less of a lead against the rest of the industry than it did in previous years. Perhaps naturally, he didn’t commit right away to revert to being an open-source initiative again, instead arguing without going into significant detail that a “different approach” is need for open-sourcing code.
Another challenge to the idea of “closed-source” corporate giants lies in how LLMs work. LLMs are “trained” to give responses to queries via databases (or “training datasets”) created by essentially “scraping” the internet for human-written material. As per former OpenAI researcher-turned-whistleblower Suchir Balaji8, this includes everything from pirated book archives and content behind paywalls to user-generated content from platforms like Reddit and copyrighted materials without explicit permission.
OpenAI responded9 to the New York Times (which has published Mr. Balaji’s account and has also sued both OpenAI and Microsoft for using its content to train its chatbots) by officially stating, “We build our A.I. models using publicly available data, in a manner protected by fair use and related principles, and supported by longstanding and widely accepted legal precedents. We view this principle as fair to creators, necessary for innovators, and critical for US competitiveness.”
Around one month after the exposé was published, Mr. Balaji was found dead in his San Francisco apartment, with the police ruling it as a suicide. Mr. Balaji’s parents, both long-standing tech workers, vehemently dispute10 this verdict.
OpenAI hasn’t been the only one accused of violating copyright laws. Proof News — an investigative outlet working with Wired — determined in July last year11 that Apple, Anthropic, Nvidia, and Salesforce used YouTube’s Subtitles feature on hundreds of thousands of videos from thousands of YouTube content creators to train their models. As legal challenges mount on America’s tech giants over their wholesale usage of human-created data ostensibly for free to build out their “paid services”, both Google and OpenAI wrote to the Trump administration earlier this month12 stating that copyright, privacy, and patents policies “can impede appropriate access to data necessary for training leading models” and that allowing AI companies to access copyrighted content would help the US “avoid forfeiting” its lead in AI to China respectively. Virtually the entirety of the entertainment industry and a large number of individuals stating aggrievement by the usage of their produced work without recompense stand opposed to such a measure.
Market Trajectories Explained
With the publication of DeepSeek’s test results and subsequent actions essentially inching towards widening the world’s access to AI-relevant code development coupled with the potential for the massive usage of copyrighted/human-created work creating the looming threat of several billions in expenses by way of copyright fees and settlements on tech giants, both the “broad market” S&P 500 – which counts tech giants as prime movers in its constituent mix – as well the industry-specific Solactive Generative Artificial Intelligence Index (SOLGAIN) have been buffeted by strong headwinds since the 20th of January:
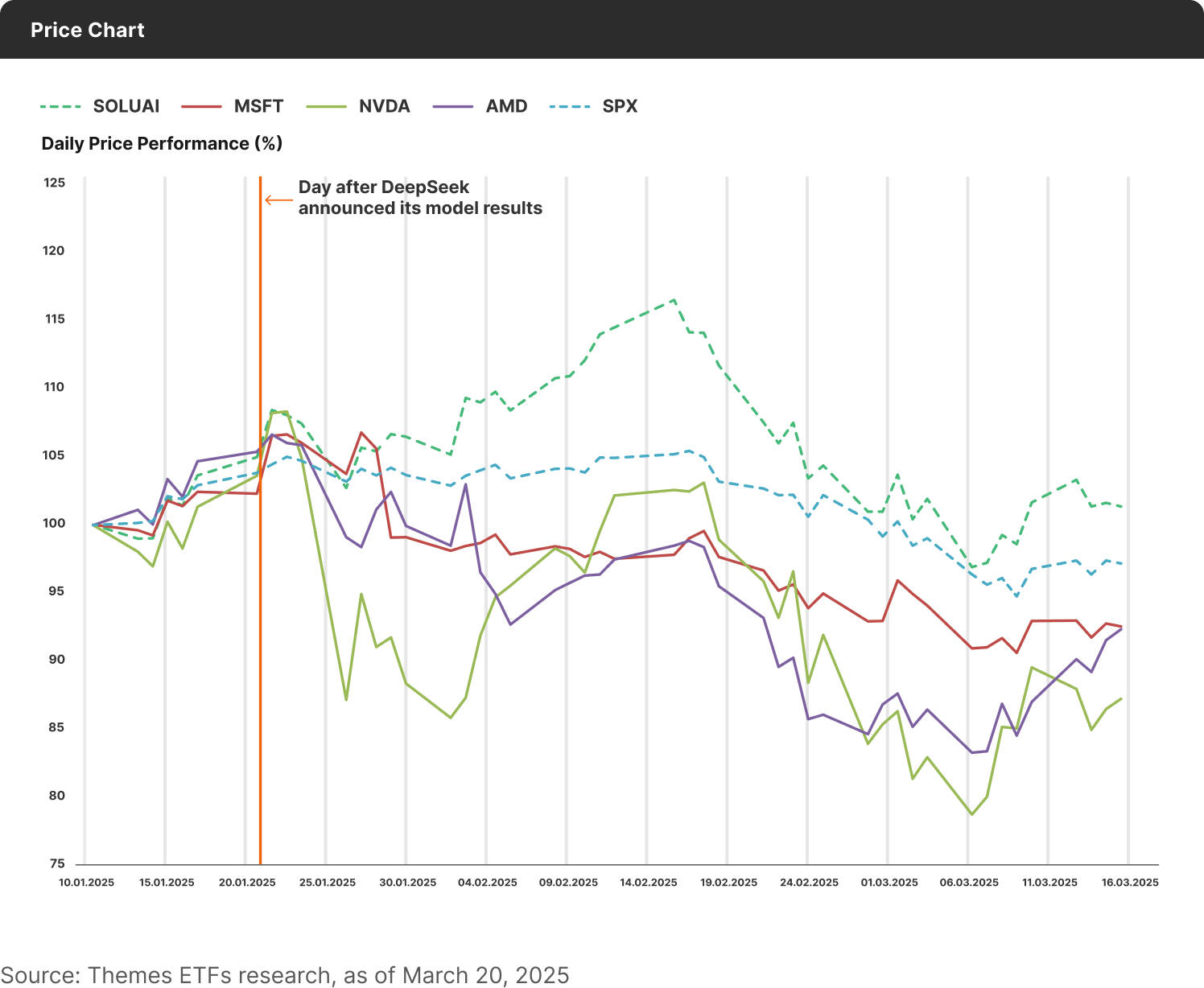
The dampening of the AI sector and the broad market is also evident in the nearly-perfect running correlations in the price performance of chipmakers such as Nvidia and AMD. For the better part of the past ten days, however, the forward outlook of AI stocks and the market received some support from the Federal Reserve as it prepared to chair its latest rate-setting Federal Open Market Committee.
The Committee’s decision met consensus market expectations prior to the release of the decision13: rates remained unchanged for the present but at least two cuts are projected for later this year as inflationary outlook is set to heighten. As rate cuts roll in, the classical market theory holds that the incentive to hold debt assets lessens, leading to a boost in consumer borrowing/spending, thus imparting a slight tailwind to the market. Adding to this is the Federal Reserve’s decision to continue scaling back its “quantitative tightening” program wherein it holds government bonds in a bid to add liquidity to the bond market.
In Conclusion
The “AI as a product” space is fraught with uncertainty from two fronts: on a forward-looking basis, building a product will be increasingly easier as concerted open-source efforts democratize the space. While it’s an even bet on whether the Trump administration will amend copyright laws to benefit tech giants, U.S. tech giants face issues related to copyright infringement from all over the world. One such challenge comes from India wherein a large number of publishers14 (and their U.S.-headquartered partner firms) as well as news agencies have filed a number of copyright infringement cases in the Delhi High Court despite OpenAI’s protestations. The concept of “fair dealing” central15 to Indian commercial laws is generally considered more restrictive and less flexible than the U.S.’ “fair use” doctrine, with penalties and consequences potentially being much stiffer as well.
With laws differing across jurisdictions and code repositories being increasingly available for research, it’s well within the likelihood that a thousand LLMs will bloom across the world (figuratively speaking, of course) and blunt the edge touted by tech players when marketing “AI as a product”.
On the other hand, “AI as a service” — wherein tech players will cultivate usage of specific models to achieve specific results on behalf of a specific client or purpose — will be an interesting space to watch. This potential new space will likely have numerous players across the world wherein value propositions will be highly-nuanced and requiring careful analysis for forward outlook estimation.
Meanwhile, investors interested in broad exposure to the AI sector as it ebbs and flows might want to consider the Themes Generative Artificial Intelligence ETF (WISE), which tracks the Solactive Generative Artificial Intelligence Index that is currently comprised of 40 companies. For exposure to chipmakers, a variety of leveraged ETFs are available for consideration: the 2x Long AMD Daily ETF (AMDG), the 2x Long Nvidia Daily ETF (NVDG), the 2x Long ASML Daily ETF (ASMG), the 2x Long TSMC ETF (TSMG) and the 2x Long ARM Daily ETF (ARMG). These “single-ticker” ETFs provide magnified exposure to the respective stocks’ trajectories. However, since there is scope for both magnified gains and losses, these instruments are more suited for tactical investment scenarios.
Footnotes:
1”China’s cheap, open AI model DeepSeek thrills scientists”, Nature, as of January 23, 2025
2”In awe’: scientists impressed by latest ChatGPT model o1”, Nature, as of October 1, 2024
3“Deploy DeepSeek-R1 distilled Llama models with Amazon Bedrock Custom Model Import”, AWS Machine Learning Blog, as of January 29, 2025
4“Alibaba’s Qwen AI models enable low-cost DeepSeek alternatives from Stanford, Berkeley”, South China Morning Post, as of February 10, 2025
5“OpenAI is getting trolled for its name after refusing to be open about its A.I.”, Fortune, as of March 17, 2023
6“DeepSeek to open source parts of online services code”, TechCrunch, as of February 21, 2025
7“Sam Altman: OpenAI has been on the ‘wrong side of history’ concerning open source”, TechCrunch, as of January 31, 2025
8“Ex OpenAI Researcher: How ChatGPT’s Training Violated Copyright Law’, Forbes, as of October 29, 2024
9“Former OpenAI Researcher Says the Company Broke Copyright Law”, New York Times, as of October 23, 2024
10“We Want To Dig Out The Truth” – Parents Of OpenAI Whistleblower Suchir Balaji:, IndiaCurrents, as of January 28, 2025
11“Apple, Nvidia, Anthropic Used Thousands of Swiped YouTube Videos to Train AI”, Wired, as of July 16, 2024
12“OpenAI and Google ask the government to let them train AI on content they don’t own”, The Verge, as of March 15, 2025
13“Fed holds interest rates steady, still sees two cuts coming this year”, CNBC, as of March 19, 2025
14“Hearing in Copyright Case Against OpenAI Brought by Indian Publishers Set for March”, Tech Policy Press, as of February 14, 2025
15“AI and Fair Use: Navigating Legal Challenges in India and the United States”, Institute of Intellectual Property Research and Development, as of January 23, 2025



